

an Edgify Research Team Publication
In the first post of this series, we presented two basic approaches to distributed training on edge devices. In the second, we explored compression methods for those approaches. Diving deeper into the real-world challenges of these training methodologies, we now introduce a problem with common architectures that arises from certain common data distributions — and the solution we have found for it.
Non IID Data Distribution
Training at the edge, where the data is generated, means that no data has to be uploaded to the cloud, thereby maintaining privacy. This also allows for continuous, ongoing training.
That being said, keeping things distributed, by its very nature, means that not all edge devices see or are privy to the same data sets. Take Amazon Go, for example. Their ceiling cameras capture different parts of the store, and hence different types of products. This means that each camera will have to train on a different dataset (and will therefore produce models at varying levels of quality).
In the distributed setting, then, there is no guarantee that the data will have identical distributions across the different devices. This presents a great challenge for schemes that rely on global statistics.
One such component which is extremely common in modern architectures, is that of a batch normalization layer. We show that batch norm is susceptible to non-IID data distribution and investigate alternatives. Our focus is on a distributed training setup with a large number of devices and hence a large batch training.
The Impact on Batch Normalization

Batch Normalization [1] layer performs normalization along the batch dimension, meaning that the mean and variance of each channel are calculated using all the images in the batch. Normalizing across the batch suffers inaccuracies when running prediction and the batch size reduces to 1. In order to address this, In prediction the layer uses mean and variance values that were aggregated over the entire data set during training. When training is distributed and each device has its own local data, the batch also becomes distributed and each device trains on a local batch before global aggregation. The normalization performed by Batch Normalization during training is on the local batch statistics while the running mean and average is aggregated globally. Thus, when the data is non identically distributed, the batch statistics of each device do not represent the global statistics of all the data, making the prediction different than the training. Training a deep neural network with batch normalization on non IID data is known to produce poor results [5].
Group Normalization to the Rescue
Group Normalization [3][4] is an alternative to Batch Normalization which does not use the “batch” dimension for normalization. It has been proposed for cases where normalizing along the batch dimension is not appropriate. For example, at inference time or when the batches are too small for accurate statistics estimation. Group Normalization works the same way for training and prediction. It divides the channels of each image into groups and calculates the per-group statistics for each image separately. Since the statistics are computed per-image, Group Normalization is completely invariant to the distribution of data across the workers, which makes it a suitable solution for non IID cases.
In the experiments section we investigate the effect of training Resnet using Group Normalization (in place of Batch Normalization) in a non-IID scenario. Our investigation focuses on training in a large batch scenario simulating a large number of machines. We show that as the batch size increases, the Group Normalization variant of Resnet shows an increasing degradation in validation accuracy. This could be attributed to Group Normalization losing some regularization ability in comparison to Batch Normalization [3]. We found similar degradation happening when using other normalization methods, such as Layer Normalization or Instance Normalization.
Training Without Normalization — Fixup Initialization
A recent paper [6] suggests that deep neural networks can be trained without layer normalization, by properly rescaling the weights initialization. The paper maintains that using common initializations leads to exploding gradients on very deep networks at the beginning of training. Similar to Batch Normalization, the paper also adds learned scalar multipliers and scalar biases to the neural network architecture. Using these changes to the weight initialization and the architecture, the authors were able to train Resnet without the use of batch normalization layers, achieving SOTA results. In what follows, we term the resulting network Resnet-Fixup.
In our experiments, training Resnet-Fixup using large batches shows sensitivity to increasing the learning rate, with training tending to suffer from exploding gradient when the learning rate is increased linearly with the batch size (as is commonly done [9]). However, we were able to train Resnet-Fixup with large batches on CIFAR10, achieving SOTA accuracy, using a carefully-tuned learning rate strategy, as we detail in the experiments section.

The Experiments
Non-IID
In order to simulate non-IID training on CIFAR10 (which has 10 classes), we used 10 devices for training, dividing the data so that each device gets images from only two classes. We trained with batch size of 320, using SGD, with a learning rate of 0.1, momentum of 0.9, and weight decay of 5e-4.
We trained using Vanilla Resnet18 on IID data as reference. All other networks were adaptations of Resnet18 for Group Normalization and Resnet-Fixup, as previously explained.
Figure 2 shows the results. We see that training Vanila Resnet18 in this non-IID scenario produces random predictions on validation. However, both Group Normalization and Resnet-Fixup are unaffected by the data distribution. The validation accuracy for group-norm Resnet18 on Non IID data is a bit lower than the IID case. This is the result of the loss in regularization when moving to Group-Normalization. Next we will see that the degradation in accuracy increases as the batch size is increased.
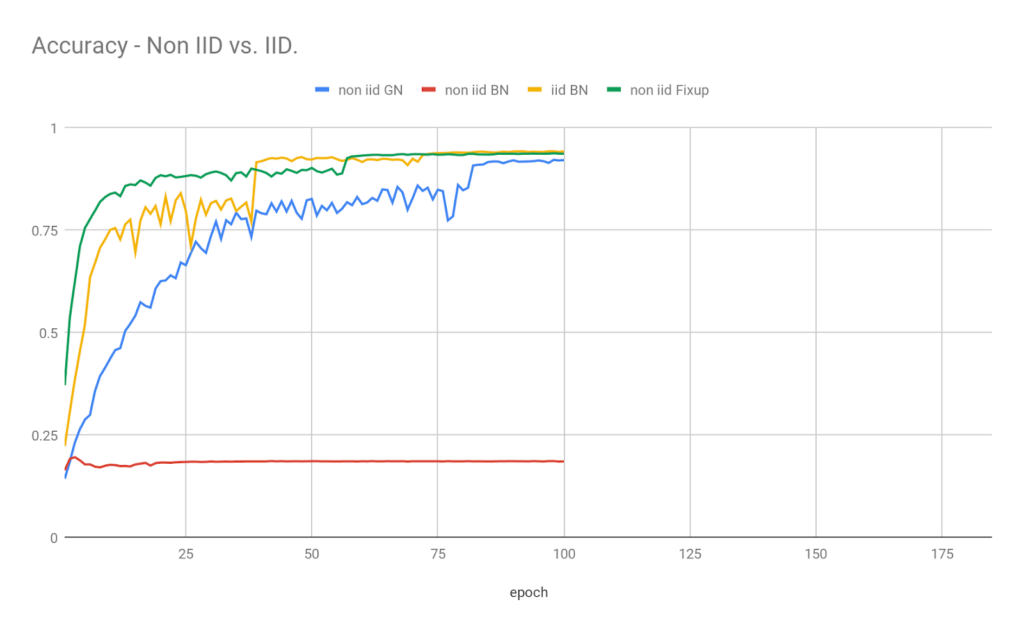
Figure 2: Validation accuracy of the IID and Non IID case. The reference (iid BN) is Vanilla Resnet18 trained on IID data. The rest are Resnet18 and variants of Resnet18 (GN for group norm and Fixup for Resnet-Fixup) trained on non IID data. While training with Batch-Norm leads to random results (non iid BN) Group Norm and Fixup resnets achieve accuracy similar to the IID batch-Norm scenario with Group Norm a bit lower.
Large batch training
We examine the effect increasing the training batch size on our two solutions, namely Group Normalization and Fixup initialization. We train Resnet18 on CIFAR10 with batch size of 128, 1k, and 2k.
For Group Normalization, we used SGD with a learning rate of 0.1, momentum of 0.9, and weight decay of 5e-4. For the batch size 128, learning rate was reduced on plateau. For batch sizes 1k and 2k we used warmup to increase the learning rate linearly from 0.1 to 0.8 and 1.6 respectively over 6 epochs and then reduce learning rate on plateau.
For Fixup, we trained with SGD with momentum and weight decay as in the Group Norm case. Learning rate for the 128 baseline was 0.1 and then reduced on plateau. For the 1k and 2k cases, we experienced exploding gradient when we tried to increase the learning rate linearly with the batch size (as was done for Group Normalization). So we used warmup from 0.01 to 0.1 for the first 20 epochs and then reduce on plateau. Training Resnet Group-Normalization using this learning rate policy did not produce different results.
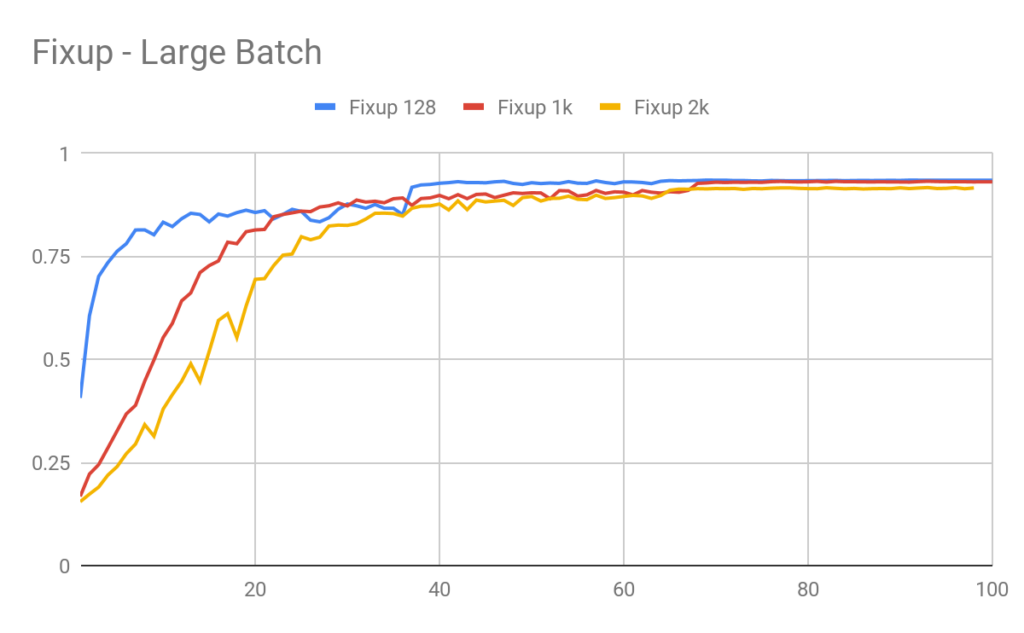
In Figure 4 we see that the Group Normalization Resnet accuracy degrades as the batch-size is increased. In Figure 5 we see that using Fixup initialization we were able to able to train with little loss of accuracy loss.
Results are summarized in table 1.

Validation accuracy for large batch training on CIFAR10 with Resnet18 after 100 epochs.
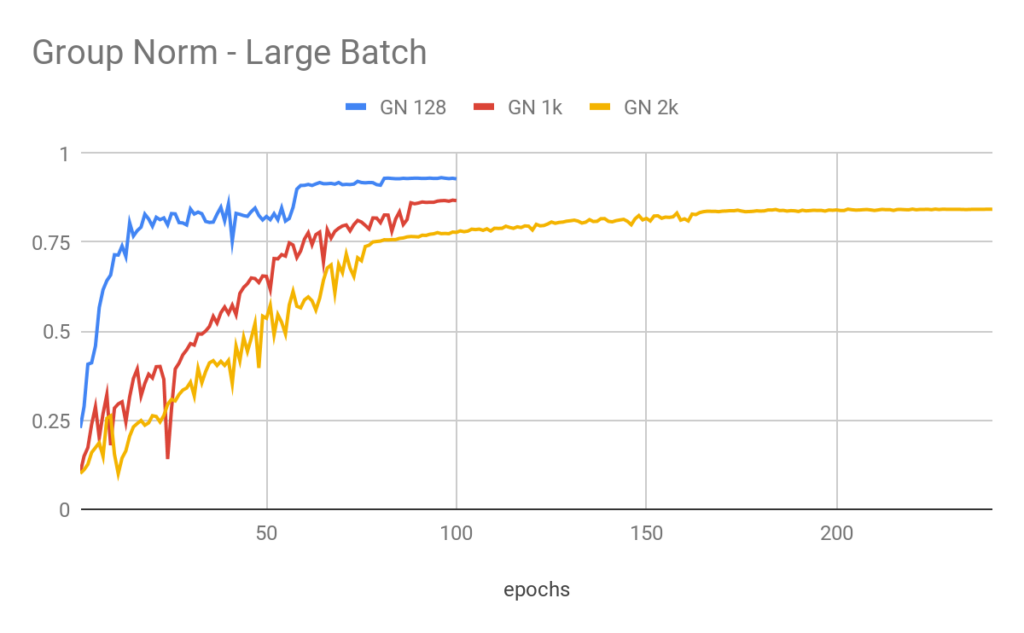
Figure 3: Validation accuracy for Resnet18 with Group Normalization on large batch training. Accuracy drops as batch size increases
Federated Learning
To conclude, we would like to address an additional challenge of training on non IID data with Federated Averaging. In the scenario described above where each device has data from different classes the models drift apart and suffer from catastrophic forgetting. This phenomena becomes more pronounced as the aggregation frequency is reduced.
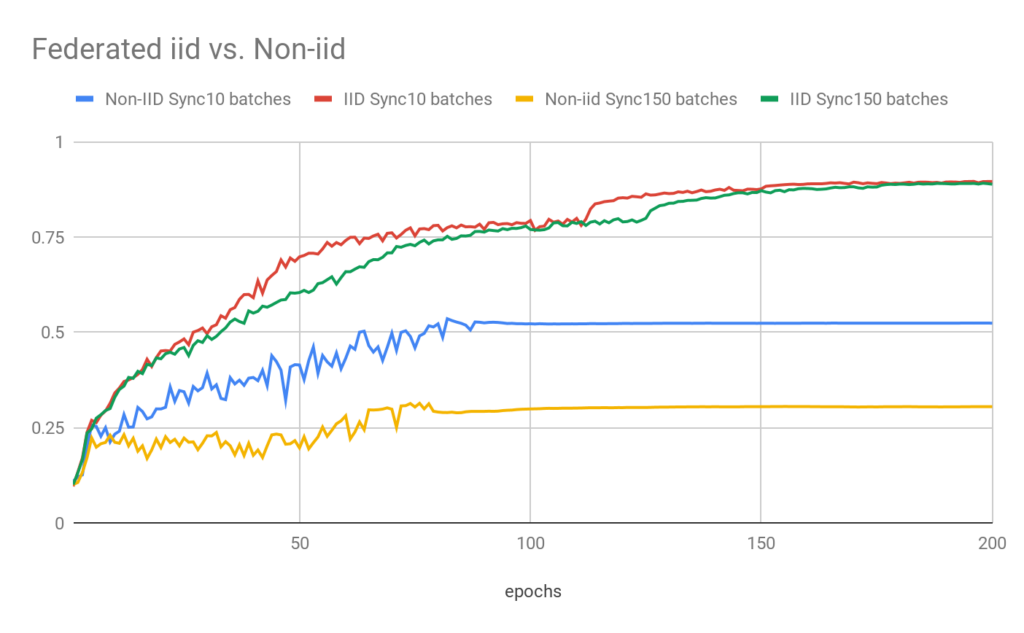
We use the above Non-IID setup to train Resnet18 with group normalization layers using Federated Averaging. Each device has 5000 images, and the local batch size is 32. To test how synchronization frequency effects training, we synchronize the models by aggregation every 10 and every 150 batches.
Figure 3 shows the results of the non IID data against the IID case. We see that catastrophic forgetting reduces the validation accuracy to nearly 50% for the 10 batch synchronization frequency while when synchronization jumps to 150 batches devices only learn their local data.
Conclusion
The unconstrained nature of data distribution on the edge poses some major challenges for on the edge training. We showed that some of today’s most prolific neural network architectures fail when training on non IID data.
As we showed, architectures that do not use batch normalization entail searching for new hyper parameters for the training algorithms as well. This point is further aggravated when training with the Federated Averaging algorithms since non IID distribution causes catastrophic forgetting. We believe that new algorithms will need to be developed and this will be a matter for future research.
This series of articles regarding distributed learning was written by the Edgify research team. Feel free to join the conversation on the Federated learning facebook group!